Introduction
After a recent discussion with a colleague I decided to investigate and write a post about the factors that influence the shape of titration curves. Acid-base titration curves (graphs of solution pH against volume of titrant added) will be discussed as these are the most common type encountered at high school, but much of what follows can be generalised to other types of titration. For a more in-depth analysis of these and other methods, Vogel’s Quantitative Chemical Analysis is a good place to start.
The shape of an acid-base titration curve has a direct influence on many aspects of a titration including titrant/titrand choice, indicator choice, whether an indicator is appropriate at all, or which equivalence point is easier to detect if there is more than one. The pH of an acid or base solution is affected by both the strength of the acid or base and its concentration, so it should be unsurprising that both of these affect the shape of an acid-base titration curve (n.b. strength is not the same thing as concentration, if you’re not sure about the difference it’s probably worth taking the time to sort that out before continuing).
High school students should probably be familiar with titration curves for monoprotic strong acid-strong base, weak acid-strong base, strong acid-weak base and possibly weak acid-weak base, all at concentrations around 0.1 M. These are presented in Fig. 1-4 below (generated with the wonderful CurTiPot).

Fig. 1: 0.1 M HCl vs 0.1 M NaOH
Features:
- neutral equivalence point pH
- very sharp change in pH either side of the equivalence point (the near vertical section from pH 4 to 10 at 25 mL)
- can detect the equivalence point using e.g. bromothymol blue, as shown on the graph (yellow at pH 6.0, blue at pH 7.6)
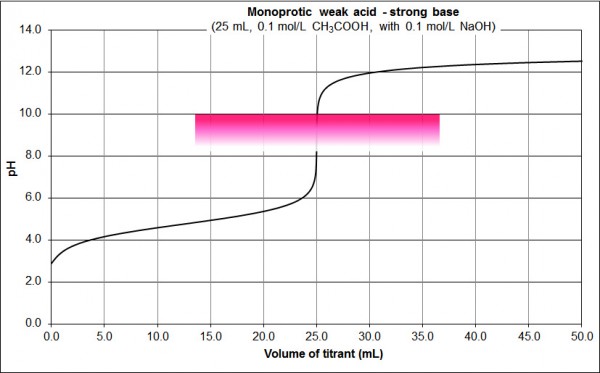
Fig. 2: 0.1 M CH3COOH vs 0.1 M NaOH
Features:
- basic equivalence point pH
- sharp change in pH either side of the equivalence point (the near vertical section from pH 8 to 10 at 25 mL, but contrast the pH change in this vertical region to that of Fig. 1)
- can detect the equivalence point using e.g. phenolphthalein, as shown on the graph (colourless at pH 8.2, pink at pH 10.0)

Fig 3: 0.1 M HCl vs 0.1 M NH3
Features:
- acidic equivalence point pH
- sharp change in pH either side of the equivalence point (the near vertical section from from pH 4 to 6 at 25 mL, but contrast the pH change in this vertical region to that of Fig. 1 and compare with Fig. 2)
- can detect the equivalence point using e.g. methyl red, as shown on the graph (red at pH 4.4, yellow at pH 6.2)

Fig. 4: 0.1 M CH3COOH vs 0.1 M NH3
Features:
- ~neutral equivalence point pH (depends on the relative strength of the weak acid and weak base)
- gradual change in pH either side of the equivalence point (contrast Figs. 1-3)
- difficult to detect equivalence point using conventional indicators as the colour change is gradual (alternatives include coulometric, thermometric or conductimetric titrations; use of mixed indicators; or simply titrating with a strong acid/base).
Acid/base strength effects: monoprotic acids and monobasic bases
As can be seen by comparing fig. 1 and 2 above, acid/base strength is one variable that affects the shape of titration curves.
The following graph shows the effect of acid strength on the shape of the titration curve. Acid strength can be measured by the acid’s pKa: smaller pKa = stronger acid, larger pKa = weaker acid. All concentrations are 0.1 M (the effect of concentration will be investigated later).

Fig. 5: 0.1 M monoprotic acids vs 0.1 M NaOH, pKa variation
Features:
- The strongest acid (brown, pKa = -7, e.g. HCl) curve is as per Fig. 1 above; the pH changes rapidly either side of the equivalence point.
- Successively weaker acids shift the pH of the equivalence point higher, and the pH change either side of the equivalence point is less pronounced.
- The acetic acid (pKa = 4.76) curve, as per Fig. 2 above, would be between the lilac pKa = 4 and royal blue pKa = 5 curves.
- The dark green pKa = 7 curve, representing an acid with a pKa of 7, has a rapid pH change of only about 1.5 at the equivalence point. This is about the limit for all but the sharpest indicators.
- Weaker acids than this (i.e. the fluoro green pKa = 8 curve and above) only show a gradual change (if indeed any at all) in pH around the equivalence point.
A similar range of curves is found for the titration of the conjugate bases of these acids with hydrochloric acid (the pKa values indicated are for the parent acids, in the same order as in Fig. 5). Again, all concentrations are 0.1 M.

Fig. 6: 0.1 M monobasic conjugate bases vs 0.1 M HCl, parent acid pKa variation
Features:
- The order of strengths is effectively swapped
- The conjugate bases of the weakest acids from Fig 5 (i.e. the fluoro green pKa = 8 curve and above) now show a sharp change in pH either side of the equivalence point.
- The dark green pKa = 7 curve has a rapid pH change of only about 1.5 at the equivalence point. Again, this is about the limit for all but the sharpest indicators.
Acid strength effects: diprotic acids
Diprotic acids can give rise to quite different titration curves, depending on the absolute and relative strengths of each dissociation.
The following graph shows the different titration curves from acids with
- a strong first dissociation: pKa1 = -3
- variable second dissociation strength: pKa2 = 2 (pink curve), pKa2 = 7 (dark green curve) or pKa2 = 12 (black curve).
Again, all concentrations are 0.1 M.

Fig. 7: 0.1 M diprotic acid (pKa1 = -3, pKa2 = 2, 7 or 12) vs 0.1 M NaOH
Features:
- Only one equivalence point (at 40 mL) is seen when both the first and second dissociations are strong (e.g. the pink pKa2 = 2 curve)
- When the first dissociation is strong and the second moderately weak, it is possible to detect two equivalence points, one at 20 mL and one at 40 mL (e.g. the dark green pKa2 = 7 curve).
- Only one equivalence point (at 20 mL) is seen when the first dissociation is strong and the second very weak (e.g. the black pKa2 = 12 curve).
The following is a similar graph with smaller pKa2 spacing:

Fig. 8: 0.1 M diprotic acid (pKa1 = -3, pKa2 = 2-12) vs 0.1 M NaOH
Features are similar to Fig. 7:
- Only one equivalence point (at 40 mL) is seen when both the first and second dissociations are strong (e.g. the pKa2 = 2 and pKa2 = 3 curves)
- When the first dissociation is strong and the second moderately weak, it is possible to detect two equivalence points, one at 20 mL and one at 40 mL. Which one is sharper depends on the relative weakness of the second dissociation.
- Only one equivalence point (at 20 mL) is seen when the first dissociation is strong and the second very weak (e.g. the pKa2 = 11 and pKa2 = 12 curves).
A similar effect is seen when the first pKa is weaker (e.g. pKa1 = 4):

Fig. 9: 0.1 M diprotic acid (pKa1 = 4, pKa2 = 5-12) vs 0.1 M NaOH
Concentration effects: monoprotic acids

Fig. 10: monoprotic strong acid, X M (pX = -1 – 5) vs X M NaOH
Features:
- The lower the acid/base concentrations, the less pronounced the pH change either side of the equivalence point.
- Somewhere between pX = 3 and 4 is about the limit for all but the sharpest indicators
For a weak acid similar features are observed, except that a higher concentration of acid and base is required to give an equivalent change in pH either side of the equivalence point. This makes sense given that the pH change either side of the equivalence point is already less pronounced for a weak acid than it is for a strong acid (compare Figs. 1 and 2).

Fig. 11: monoprotic weak acid (pKa 4.76), X M (pX = -1 – 5) vs X M NaOH
Concentration effects: diprotic acids

Fig. 12: X M diprotic acid (pX = -1 – 5, pKa1 = -3, pKa2 = 2) vs X M NaOH
Features:
- As above, the lower the acid/base concentrations, the less pronounced the pH change either side of the equivalence point.
- As above, somewhere between pX = 3 and 4 is about the limit for all but the sharpest indicators
- At pX = -1 (i.e. a concentration of 10 M) the first equivalence point becomes detectable
Consider again Fig. 7 (0.1 M, reproduced immediately below) and compare with Fig. 13 below it (0.001 M):
Fig. 7: 0.1 M diprotic acid (pKa1 = -3, pKa2 = 2, 7 or 12) vs 0.1 M NaOH

Fig. 13: 0.001 M diprotic acid (pKa1 = -3, pKa2 = 2, 7 or 12) vs 0.001 M NaOH
Features:
- The two curves with a single equivalence point (the pink pKa2 = 2 and black pKa2 = 12 curves) still have detectable equivalence points, although the pH change is less pronounced than it is with 0.1 M acid and base.
- At the lower concentration, neither equivalence point for the pKa2=7 acid is sufficiently sharp for indicators such as methyl red or phenolphthalein.
Summary
As we have seen through the examples above, the pH and thus the shape of a titration curve, is a function of:
- acid strength
- base strength
- acid/base concentration
For polyprotic acids, the relative strength of each acid dissociation as well as the strength of these in comparison to the base strength further complicates matters.
Putting all of this together, the titration of X M phosphoric acid (pKas 2.15, 7.20 and 12.35) with X M sodium hydroxide (for pX between -1 and 5) shows only two equivalence points, neither of which is particularly sharp even at high concentrations:

Fig. 14: X M phosphoric acid vs X M NaOH (pX = -1 – 5)
As a final example, consider the titration of X M citric acid (a triprotic acid with pKas of 3.14, 4.75 and 5.41) with 3X M sodium hydroxide, for pX between 0 and 5. You can do this titration at home, as I outlined in a previous post. Given the proximity of its three pKa values (and their relative strength), it should not be surprising that only one equivalence point is detectable for all of these concentrations.

Fig. 15: X M citric acid vs 3X M NaOH (pX = 0 – 5)
I hope you have found these examples useful; any comments are greatly appreciated!

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Australia License